4.计划和执行 病例对照研究在制订计划和执行时应注意以下问题:
(1)主要假设的说明是否清楚、简明而且可以检验?
(2)疾病与暴露变量的定义清楚、明确否?
(3)是否拟探索剂量反应关系和多个危险因素的联合作用?
(4)为解答问题所需之病例数和对照数能否得到?这样大小的样本能查出的最小相对危险度是多少?与估计的相差多少?[参考附录五(四)节]。
(5)病例来源及抽样技术明确否?病例数与对照数之比是多少?匹配否及匹配哪些变量?
(6)调查表(问卷)是否已包括打算测量的所有变量并能够收集到需要的数据?其详尽程度是否已足供分析之用?
(7)医院记录(病历)及其他来源的信息、从体检、实验室检查、病理切片等获得的数据需表格记录否?
(8)调查表经过试用否?其真实度与可靠度(重复性)经评估否?访问时拟使用帮助回忆的实物、模型或图片否?
(9)调查员、质控员、病历摘录员、编码员的工作手册已编好否?须专门培训否?
(10)组织机构、人员、设备、经费落实否?
(11)协作单位有书面协议否?有关领导机关已批准否?将诊断根据(切片、标本、影像图片等)送到主持单位复核安排妥当否?
(12)实验室检验项目或用仪器检测的项目所用仪器、方法、试剂是否符合标准?结果的真实度与可靠度经过考核否?
(13)经治医院、医生是否同意提供病例和对照?是否必须取得研究对象在了解情况后的书面同意?资料、数据怎样保密?怎样保存?
5.数据分析 须分析什么项目,计算哪些统计量,用什么统计学方法,用手工(计算器)还是计算机,如用后者怎样建数据库和用什么软件包,等等,都应包括在设计之中,手工计算时还应拟好相应表格。现在计算机及统计软件包的应用渐趋普及,过去很难进行的一些复杂的统计检验现在很快就可完成并打印出结果还可绘出统计图。但是,一些流行病学专家主张先用手工计算基本内容以熟悉数据,然后再由计算机作复杂运算(多元分析)。
本节要介绍的是基本原理和基本方法,无论用手工或机器运算,这些都是应熟悉的。
病例对照研究数据分析的中心内容是比较病例和对照中暴露的比例并由此估计暴露与疾病的联系程度,并估计差别与联系由随机误差造成的可能性有多大,特别要排除由于混淆变量未被控制而造成虚假联系或差异的可能。进一步,还可计算暴露与疾病的剂量反应关系,各因子的交互作用(对一种因子的暴露会不会影响对另一种因子的效应),等等。非匹配和匹配设计的研究,数据的分析方法有一些不同。
(1)非匹配数据的分析:首先要检验病例组与对照组在某些主要特征(即可能成为混淆因子的特征)的构成上是否没有显著差别(均衡性检验)。
1)联系的显著性与联系强度:某个因素与某种结局(患病或死亡)之间的联系是否有统计学显著性,常用χ2检验。最简单的情况是因素与结局都只分为“有”或“无”两类,数据可纳入一张2×2表(即四格表,又称四格列联表),例如表4-1。χ2检验可用四格表专用公式(式4-1)。但χ2值的大小并不表示联系的强度。χ2≥3.84时,设两者无联系的假设(无效价设,H0)被否定,而转向存在联系的假设(备择假设,HA),这个判断错误的可能性为≤0.05(即ρ≤0.05)。χ2值越大,判断错误的可能性越小。
表4-1 危险因子与疾病的联系
|
患病 |
有暴露史 |
无暴露史 |
合计 |
|
有 |
a |
b |
a+b |
|
无 |
c |
d |
c+d |
|
合计 |
a+c |
b+d |
a+b+c+d=n |
统计学显著性可以评价在多大程度上可用机会解释所观察到的联系。但如数据本身存在系统误差,统计学显著性检验就无意义,因为它不能区别联系的真或假(由偏倚、混淆所致的联系)。此外,统计学显著性检验结果极大地受样本含量的影响,样本小则随机变异大;即使实际上暴露的作用很大,也会导致“不显著”的结论。所以“不显著”应理解为“不足以否定无效假设”。
 (式4-1)
(式4-1)
现况调查和队列研究(见本章“二、队列研究”)可以计算暴露者(或具某特征者)和未暴露者(或不具某特征者)的患病率或发病率,因为分子数与分母数是已知的。也可以计算相对危险度(见本章公式4-11)。这是联系强度的一个指标。
但是病例对照研究因为不能计算出患病率或发病率所以不能计算相对危险度,但可用另一个联系强度指标――比数比(odds ratio,又译比,值比、优势比,缩写为OR)。比数比是两个比数之比。比数(odds)是表示一个事件发生机会大小的一种指标。以表4-1为例(字母代表数目),如果是队列研究与现况调查,可以计算发病(或患病)比数,暴露组的这个比数为α/c,未暴露组的这个比数为b/d。如果是病例对照研究,可以计算暴露比数,在病例组是α/b,在对照组是c/d。两组比数之比称为比数比,
OR =(α/b)/(c/d)=αd/bc
或
OR =(α/c)/(b/d)= αd/bc.
(式4-2)
这个比正好是四格表中两条对角线上四个数字的交叉乘积αd与bc之比,所以四格表数据的OR又称交叉乘积比。OR可用于队列研究,但更重要的是用于病例对照研究。在少见病,OR可以当作RR去解释,即OR近似于RR。因在此情况下总体内不论暴露组或未暴露组中患病者的人数(分别记为A与B,用大写字母区别于样本数据的小写字母)都远少于未患病者的人数(C与D),所以在总体内A+C→C,B+D→D,于是

因为从随机样本的α/c与b/d可以估计A/C或B/D,所以可用αd/bc估计AD/BC,也就是说可以用OR作为RR的估计值。
暴露组与未暴露组的发病率或死亡率之比称为率比(rate ratio)。两组发病概率之比称为危险度比(risk ratio)。在少见病,这两个比和比数比均近似,可统称为相对危险度。
从OR(或RR)值可估计暴露与疾病的联系程度。这种联系的稳定性,即随机变异的大小可用显著性检验的ρ值和可信限来估计。OR是用来估评暴露与疾病的联系程度或即暴露作用强度的一个点估计值(0~∞),但为估计这个值受随机变异影响的程度,最好同时算出可能包括真值(参数)的一个取值范围,表示以一定程度的信心估计参数值所在的范围,称为可信限或可信区间(confidence interval)。计算方法详见附录五。如果可信限包括了无效值(OR=1),说明该联系无显著性;可信限的宽度又反映点估计值(OR)的稳定性,范围宽说明估计值不稳定,也就是随机变异程度大。所以现在认为仅计算出点估计值的意义有限,应同时计算出其可信限。
2)分层数据分析:病例对照研究在设计阶段可采用的控制混淆因素的方法有限制与匹配。限制是指对采用研究对象的范围加以限制,如混淆因素为列名变量(离散变量)可限定只采用某一类或几类对象(例如性别、职业、地区等),如为连续变量可限定只采用某一范围内(例如年龄组、段)的对象。其目的都是得到比较匀质的研究对象。如果一个因素在各对象间无差别或差别很小,它就不可能起到混淆作用,也就是得到了控制。可在分析阶段采用的控制混淆因素的方法有分层、标准化和多元分析。其中以分层分析最常用。
分层就是把样本按照一个或更多个混淆因子的暴露有无或作用程度而划分为若干个组,也就是“层”,再分别在每一层内分析所研究暴露与疾病的联系,计算各层的比数比(记为OR);
表4-2 第i层内病例与对照按暴露有无分组
|
组别 |
病倒 |
对照 |
合计 |
|
暴露 |
αi |
bi |
m1i |
|
未暴露 |
ci |
di |
m0i |
|
合计 |
n1i |
n0i |
ni |
如果各层 具有齐性[齐性检验方法见附录五(一)],则可以计算总的即各层OR的合并OR。因其方法系Mantel与Haenszel两人所开发,所以通常记作ORMH 。因在同一层内作为分层标志的因子对病例组与对照组的作用都是相同的,所以对所研究的暴露与疾病的联系便不会发生混淆作用。其原理与匹配相同,实际上1:1匹配就是一种最细的分层,每层只包括一个病例与一个对照。合并OR是概括各层OR的一个指标。
合并OR的计算方法:
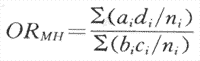
(式4-3)
ORMH可信限的计算方法及计算实例见附录五(一)。
ORMH如果不等于1,那么与1的差异是否显著?可用作显著性检验,其方法如下:
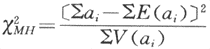
(式4-4)
式中,ai=各层四格表中的a数值,

检验假设(即无效假设)Ho:OR=1,双侧备择假设HA:OR≠1。统计量X2MH呈自由度为1的X2分布。
分层分析法举例:某地进行了一次食管癌病因的病例对照研究,共调查病例200例,人群对照776例。现分析其中饮酒与食管癌的联系,结果如表4-3。
表4-3 饮酒与食管癌的联系
|
饮酒史 |
病倒数 |
对照数 |
合计 |
|
饮 酒 |
171 |
381 |
552 |
|
不饮酒 |
29 |
395 |
424 |
|
合计 |
200 |
776 |
976 |
OR=6.11 χ2=84.29
可见饮酒与食管癌有强联系,但已知吸烟与食管癌也有强联系。为了分析饮酒与食管癌显示出的强联系是否可能与吸烟有关,或吸烟是否可能是一个混淆因子,可采用分层分析:按是否吸烟分为两组,再分析饮酒与食管癌的联系,结果见表4-4。
表4-4 饮酒与食管癌在吸烟与不吸烟者的联系
|
不吸烟者 |
吸烟者 | ||||||
|
饮酒史 |
病倒 |
对照 |
合计 |
饮酒史 |
病倒 |
对照 |
合计 |
|
饮 酒 |
69 |
191 |
260 |
饮酒 |
102 |
190 |
292 |
|
不饮酒 |
9 |
257 |
266 |
不饮酒 |
20 |
138 |
158 |
|
合计 |
78 |
448 |
526 |
合计 |
122 |
328 |
450 |
OR=10.3 χ2=53.99 OR=3.70 χ2=24.62
计算ORMH ,先用公式(4-3)计算

再用公式(4-4)作χ2检验:
χ2MH=76.84
ρ<0.00000001。用附录五公式(附式5-1)计算ORMH的95%可信限,上限为8.09,下限为3.81。用附录五(一)的Woolf法作各层ORi的齐性检验,结果说明各层间的OR差异显著,来自同一总体的可能性很小,所以ORMH不能说明吸烟、饮酒与食管癌的联系,因此是无意义的。这种齐性检验可同时检验各因素间是否存在交互作用。本例的计算过程及结果解释见附录五(一)的计算实例。
以上关于分析方法的介绍,都是以暴露有无和疾病有无这种最简单的两分变量为例。实际情况常较此复杂,有必要时读者可参考专书。




